The chi-square test is a non-parametric statistical test used for categorical data. Chi-square tests are used to make statistical inferences about categorical variables. Depending on the research question and the number of categorical variables, the specific chi-square test can differ, so it is important to identify the correct scenario for application.
The core idea behind chi-square tests is to compare observed counts with expected counts based on a population or theoretical distribution.
5.1 Hypotheses
Null hypothesis (\(H_0\)): The observed counts (\(O_i\)) and expected counts (\(E_i\)) are equal.
Alternative hypothesis (\(H_1\)): The observed counts (\(O_i\)) and expected counts (\(E_i\)) are not equal.
5.1.1 Test Statistic
The chi-square test statistic is calculated as:
\[
\chi^2 = \sum \frac{(O_i - E_i)^2}{E_i}
\]
Under the null hypothesis, this statistic follows a chi-square distribution with degrees of freedom that depend on the type of test being performed.
Intuitively:
- If the observed and expected counts are close, the test statistic is small and not significant.
- If the observed counts differ substantially from the expected counts, the test statistic is large and significant, indicating a meaningful difference between the sample and the expected distribution.
5.1.2 Assumptions
Observations are independent.
Expected counts are sufficiently large (typically greater than 5).
The chi-square distribution is defined by its degrees of freedom, which vary depending on the test design and the number of categories.
There are two main types of chi-square tests:
Goodness-of-Fit Test
Compares observed frequencies to expected frequencies for a single categorical variable.
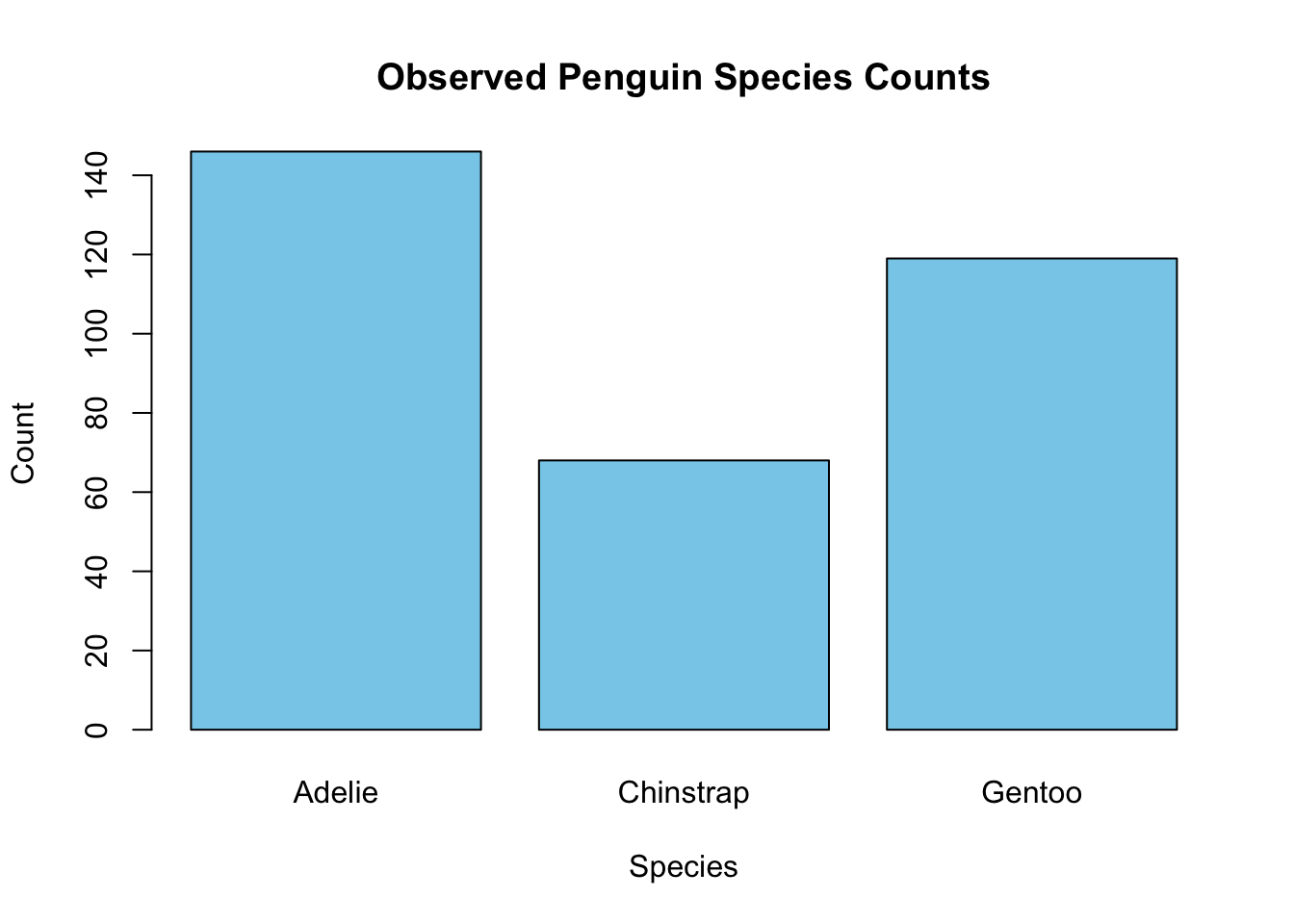
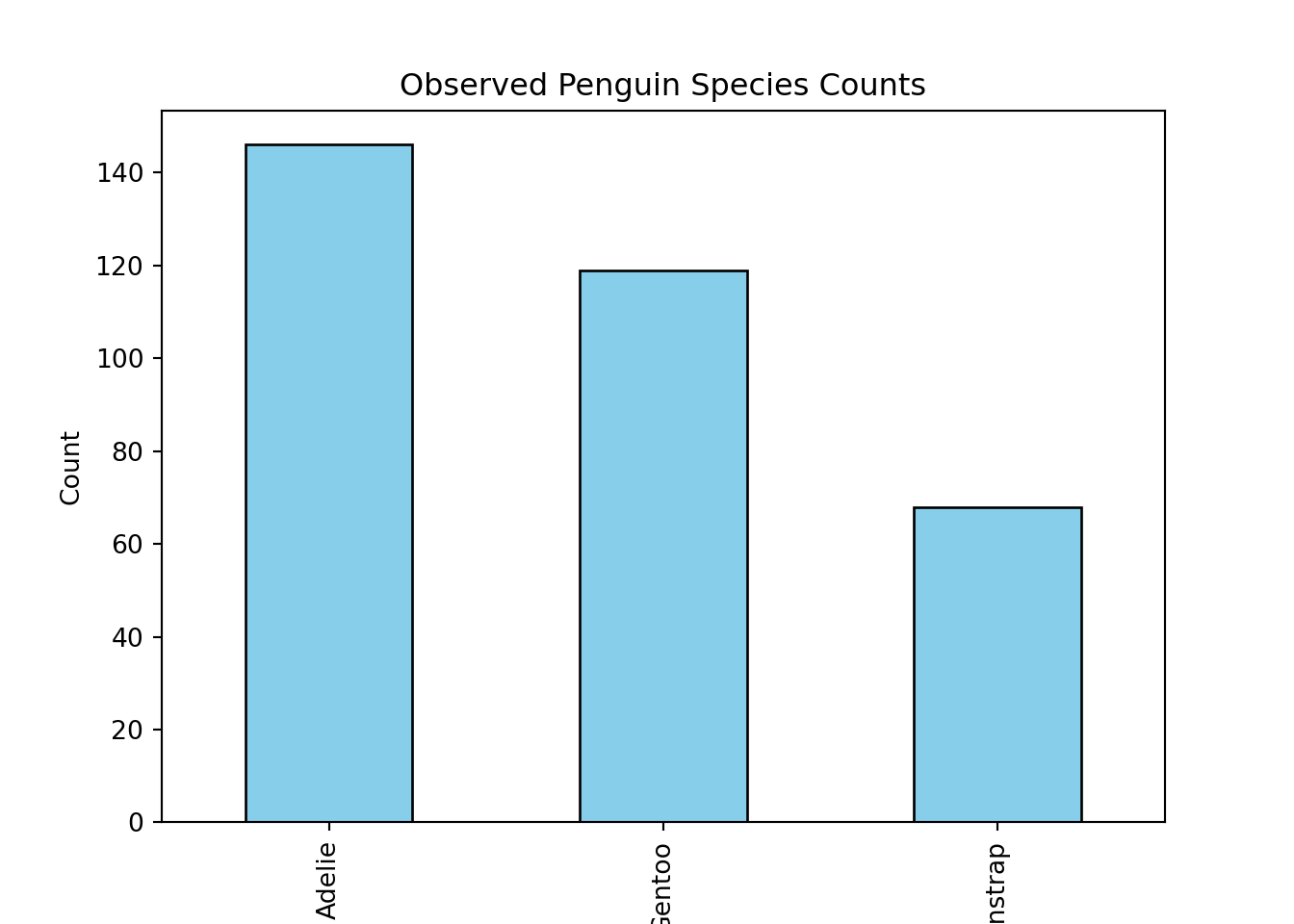
Example: Do the proportions of penguin species in the dataset match a hypothesized distribution (45% Adelie, 35% Gentoo, 20% Chinstrap)?
Test of Independence (or Homogeneity)
Tests whether two categorical variables are independent.
Example: Is penguin species independent of the island they were observed on?
5.2 (i) Chi-Square Goodness-of-Fit Test
This test examines whether the distribution of a categorical variable matches a hypothesized distribution.
5.2.1 Hypotheses
\(H_0\): The observed distribution matches the expected distribution.
\(H_1\): The observed distribution does not match the expected distribution.
5.2.2 Study Design
Suppose we hypothesize that the penguin species occur in the following proportions:
Adelie: 45%
Gentoo: 35%
Chinstrap: 20%
We want to test whether the observed species distribution in the Palmer Penguins dataset matches these proportions.
5.2.3 Data Collection & Wrangling
Here, we first load the Palmer Penguins dataset and remove any missing values to ensure complete observations. Next, we count how many penguins of each species are observed and calculate the expected counts based on our hypothesized proportions. These observed and expected frequencies will later be compared using the Chi-square test statistic.
# Expected proportionsexpected_props = [0.45, 0.35, 0.20]# Convert to expected countsn =len(penguins_clean)expected_counts = [p * n for p in expected_props]print("\nExpected counts (based on proportions):")
Expected counts (based on proportions):
print(expected_counts)
[149.85, 116.55, 66.60000000000001]
5.2.4 Exploratory Data Analysis (EDA)
Before running the statistical test, it’s helpful to visualize the observed counts. A simple bar plot allows us to see whether any species appear more or less frequent than expected, which helps build intuition about potential differences.
# Bar plot of observed countsbarplot(observed_counts, col ="skyblue", border ="black", main ="Observed Penguin Species Counts", xlab ="Species", ylab ="Count")
import matplotlib.pyplot as pltobserved_counts.plot(kind="bar", color="skyblue", edgecolor="black")plt.title("Observed Penguin Species Counts")plt.xlabel("Species")plt.ylabel("Count")plt.show()
5.2.5 Implementation
Now we apply the Chi-square goodness-of-fit test, comparing observed and expected counts. The test statistic measures how far the observed frequencies deviate from the expected ones. A large value suggests that the observed distribution differs significantly from what was hypothesized.
# Chi-square goodness-of-fit testchi2_test<-chisq.test( x =observed_counts, p =expected_props)print(chi2_test)
Chi-squared test for given probabilities
data: observed_counts
X-squared = 61.551, df = 2, p-value = 4.31e-14
from scipy.stats import chisquarechi2_stat, p_value = chisquare( f_obs=observed_counts, f_exp=expected_counts)print(f"Chi-square = {chi2_stat:.3f}, p = {p_value:.4f}")
Chi-square = 0.180, p = 0.9140
5.2.6 Interpretation
If \(p < 0.05\): Reject \(H_0\) → the species distribution differs significantly from the expected proportions.
If \(p \ge 0.05\): Fail to reject \(H_0\) → no significant difference.
5.3 (ii) Chi-Square Test of Independence
This test evaluates whether two categorical variables are independent.
5.3.1 Hypotheses
\(H_0\): The two categorical variables are independent.
\(H_1\): The two categorical variables are not independent (they are associated).
5.3.2 Study Design
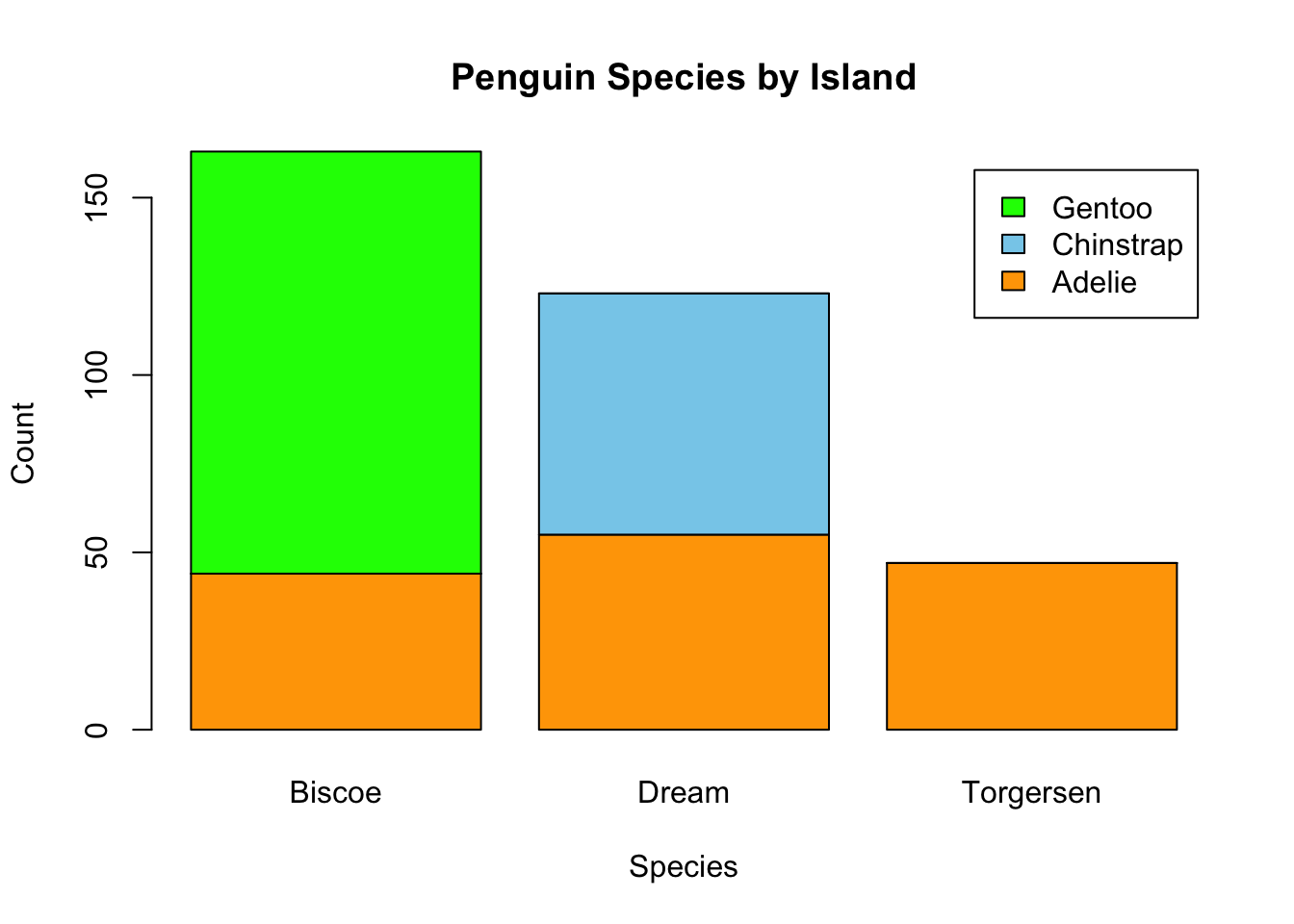
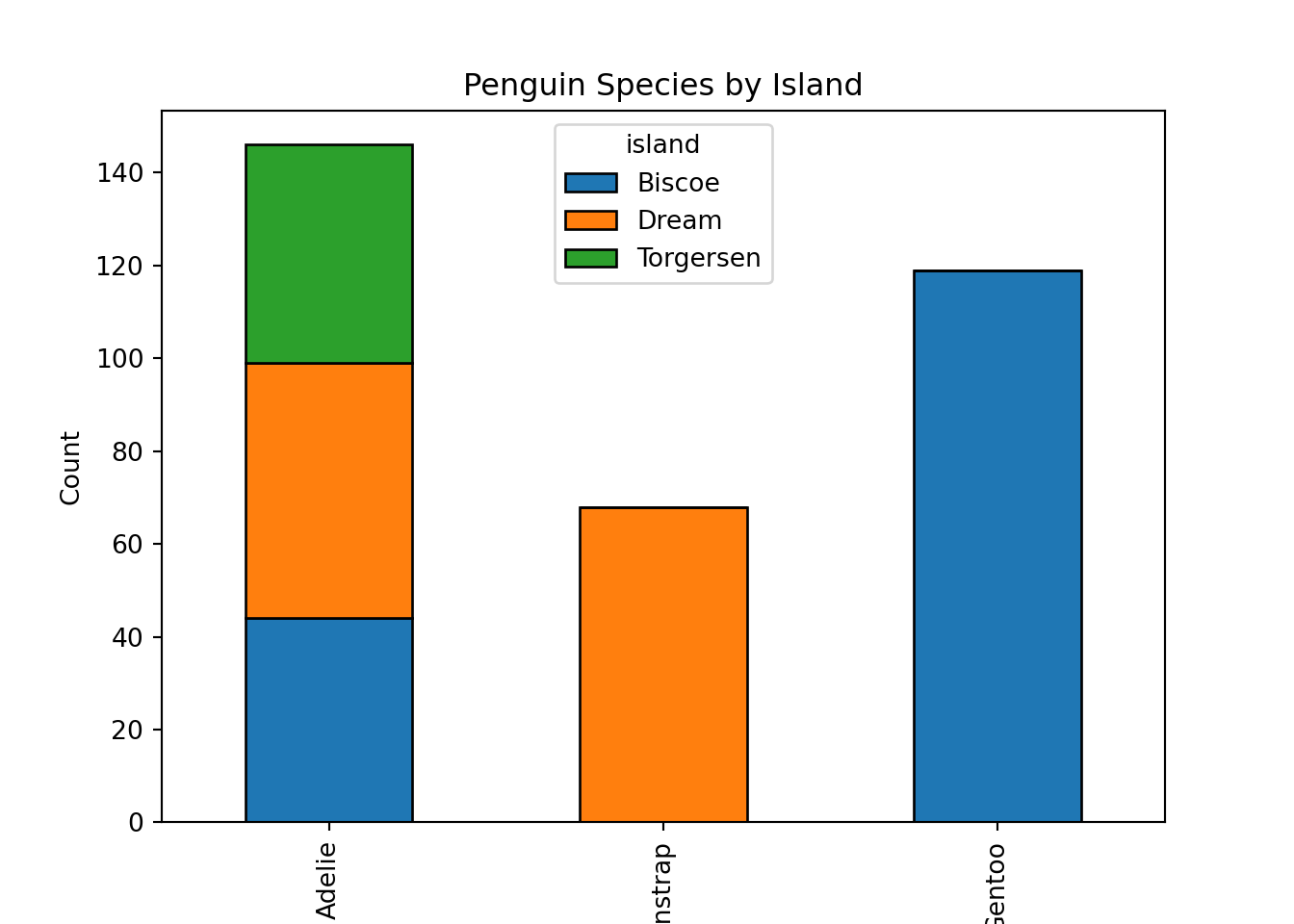
We want to test whether penguin species is independent of island — in other words, whether certain species are more common on certain islands.
5.3.3 Data Collection & Wrangling
We create a contingency table summarizing the counts of species across islands. This table serves as the basis for calculating expected frequencies and testing independence.
# Create contingency table: species vs islandcontingency_table = pd.crosstab( penguins_clean["species"], penguins_clean["island"])print("Contingency table:")
Contingency table:
print(contingency_table)
island Biscoe Dream Torgersen
species
Adelie 44 55 47
Chinstrap 0 68 0
Gentoo 119 0 0
5.3.4 Exploratory Data Analysis (EDA)
Visualizing the contingency table helps us see any apparent association between species and island. If bars differ noticeably in height across islands, it hints that species distribution might depend on island location.
# Stacked bar plot of species by islandbarplot(contingency_table, col =c("orange", "skyblue", "green"), border ="black", main ="Penguin Species by Island", xlab ="Species", ylab ="Count", legend.text =TRUE)
contingency_table.plot( kind="bar", stacked=True, edgecolor="black")plt.title("Penguin Species by Island")plt.xlabel("Species")plt.ylabel("Count")plt.show()
5.3.5 Implementation
We now apply the Chi-square test of independence to evaluate whether the distribution of species differs by island. If the test is significant, it suggests a relationship between the two categorical variables.